卷积神经网络在 ARM-CPU 上的推断计算综述
Linghan Cheung
lhcheung1991@gmail.com
(请在文章底部留下宝贵的评论和建议, Gitment会将留言以issue形式完整保存方便后续查阅)
摘要
深度学习在计算机视觉领域大放异彩,许多在传统方法下无法解决的问题正在被一一攻克。然而,高昂的计算成本也极大地限制了深度学习的使用,在移动端设备、嵌入式设备等计算资源比较拮据的平台上其计算密集的特性尤为突出。本文对现阶段,工业界所使用的深度学习推断阶段的软件操作库、计算框架等,做了充分调研,由底向上勾勒出深度学习推断阶段的技术轮廓。本文主要工作如下:
- 总结深度学习推断阶段的主要操作,指出其性能瓶颈所在;
- 从软件库层面总结现阶段可用的开源库;
- 对比各层次的软件库,做出总结。
深度学习推断的主要操作
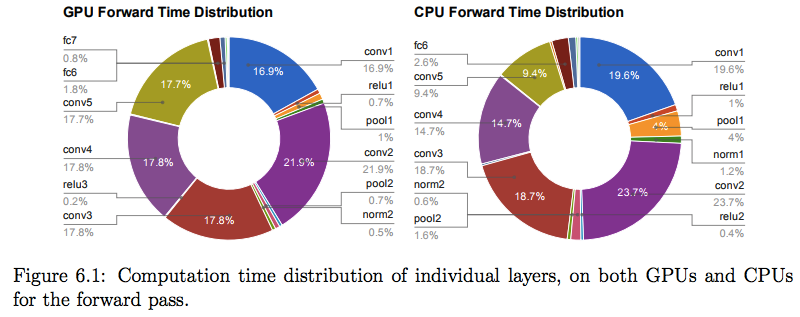
对于大部分的卷积神经网络而言,卷积层是最消耗时间的部分,而全连接层则是参数量最多的部分[2]。 如下图所示[10]为 2012 年获得 imagenet 冠军的深度神经网络结构 Alexnet 分别在 GPU 和 CPU 进行推断的性能 benchmark,由图可以看出,在 CPU 上卷积层和全连接层占用了 95% 的计算时间,而在 CPU 上卷积层和全连接层占用了 89% 的时间,如何高效地进行卷积层和全连接层的计算成为提升深度学习推断性能的关键点。
此处我们总结了业界现在进行卷积层计算和全连接层计算较为主流的方法,分别是 im2col + GEMM(Image to Column + GEneral Matrix Mutiplication),FFT(Fast Fourier Transforms),Winograd Transform。由于卷积层和全连接层的计算实现原理相仿,故此处以卷积层的计算为示例。
首先是 im2col + GEMM,这是处理卷积层计算较为直观的方法,它的核心思想是将计算转换成两个矩阵的乘法:1. 使用 im2col 将图像转换成一个矩阵;2. 使用 im2col 将卷积核转换成一个矩阵;3. 对前两步所得矩阵进行相乘操作。如下图所示:
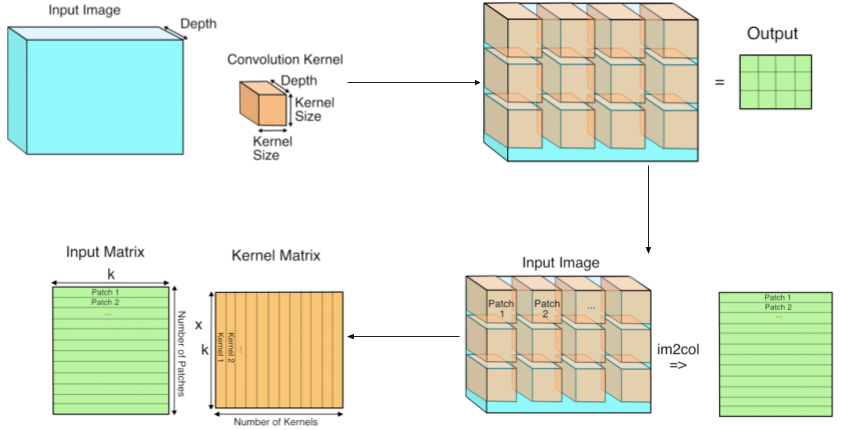
im2col 原来是 Matlab 中提供的一个函数,在处理神经网络的三通道图像输入时,它的操作就是将一个 3D 的数组转换成一个 2D 的数组,这样我们才能把图像当成一个矩阵来处理。在卷积计算中,每个卷积核的运算对象都是输入的 3D 数据中的一个个小立方体,所以 im2col 在处理图像时会根据 stride 将一个个的小立方体中的数据拷贝成矩阵中的一行。我们对卷积核进行相同的转换操作,再将得到的卷积核矩阵进行一下转置,就可以进行卷积层的运算操作了。这里 k 是每个卷积核和输入立方体的数值个数,那么假设我们要处理 1 x 3 x 160 x 160 (N x C x H x W)的一张图像,经过一个 3 x 3 x 3 x 16 (H x W x I x O) 的卷积层,stride = 1,padding = "SAME",则需要进行如下的矩阵运算:
或许你已经注意到了,如果 stride < kernel size,那么将会有大量的重复像素被包含到转换之后的矩阵之中,这对于内存而言是一个很大的消耗。这是 im2col + GEMM 进行卷积运算的一个明显缺点,不过相比起能够利用多年来科学计算工程师对大矩阵相乘优化的成果,这个缺点就显得微不足道了。im2col + GEMM 方案被很多计算框架所采用,例如贾杨清博士编写的 Caffe 框架就是这么实现的,具体请参考这篇文章:在 Caffe 中如何计算卷积?。全连接层的运算利用 im2col + GEMM 实现较为容易理解,限于篇幅所限我们这里不展开讨论。
第二个方法是基于快速傅里叶变换的卷积法(Fast Fourier Transforms)[11][12][13]。使用 FFT 进行卷积的计算,其背后的数学原理是将时域中的卷积运算转换成频域中的乘积运算,从而将运算量减少。使用 FFT 变换进行卷积计算的定义如下:
对于定义在整数 Z^2 上的二元函数 f, g,二者的离散卷积操作定义如下(此处函数 f, g 是图像像素位置到像素值之间的一个映射):
当 f, g 的支撑集为有限长度 U, V 时,上式会变成有限和(即 U, V 将决定卷积核进行计算的大小):
由卷积定理我们知道,两个离散信号在时域做卷积的离散傅里叶变换相当于这两个信号的离散傅里叶变换在频域做相乘,具体地,先将信号从时域转成频域:
\[F(f) = DFT(f(x, y)) \\ F(g) = DFT(g(x, y))\]则有(o 为矩阵逐元素相乘,经过离散傅里叶变换后得到的矩阵大小与原来的相同):
\[y(x, y) = f(x, y) * g(x, y) \leftrightarrow F(y) = DFT(y) = F(f) \circ F(g) = DFT(f(x, y)) \circ DFT(g(x, y))\]最后,我们再做一次傅里叶逆变换,将频域信号转回时域,就完成了卷积的计算:
\[y(x, y) = IDFT(F(y)) = IDFT(DFT(f(x, y)) \circ DFT(g(x, y)))\]上述过程总共进行2次 DFT(离散傅里叶变换) 和1次 IDFT(逆离散傅里叶变换),DFT 和 IDFT 的运算可以采用 FFT。要在频域中对一副图像进行滤波,滤波器的大小和图像的大小必须要匹配,这样两者的相乘才容易。因为一般卷积核的大小比图像要小,所以我们需要拓展我们的kernel,让它和图像的大小一致[13],所以需要使用循环填充的方式将卷积核进行扩展,以便最后两个信号相乘时能够大小一致。
采用上述方式进行卷积的计算,其优点显而易见——大大减少在时域中进行直接卷积运行的计算量。这种方法被一些神经网络运算库所采用,如 facebook 的 NNPACK。但是由于现代的卷积神经网络常使用 stride = 2 / 3 / ... 的卷积(上述方法为 stride = 1),所以其对卷积的方式有限制性,无论 stride 值为多少,都会进行 stride = 1 的操作,不如 im2col + GEMM 方式通用,而且当卷积核足够小、 stride 值足够大时,im2col + GEMM 的计算量将比 FFT 方法更少。各个厂商在实现其神经网络库的卷积操作所采取的方法各不相同,都有其所考虑的侧重点,如 NVIDIA 的 cuDNN 就撅弃了 FFT 这种方式,具体可参考 Chetlur, Sharan, et al. “cudnn: Efficient primitives for deep learning.” arXiv preprint arXiv:1410.0759 (2014).
第三种方法是基于 Winograd Transform。其核心思想是采用 Winograd’s minimal filtering algorithms,针对 3 x 3 的小卷积核和较小的 batch size 能达到很高的计算速度。具体可参考 Lavin, Andrew, and Scott Gray. “Fast algorithms for convolutional neural networks.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
可用的开源库
本文的重点叙述对象平台是 ARM 架构的 CPU,这是因为目前移动端常用的系统中,各个厂商之间产品的性能差异主要体现在基于 ARM 架构的 CPU 平台之上。
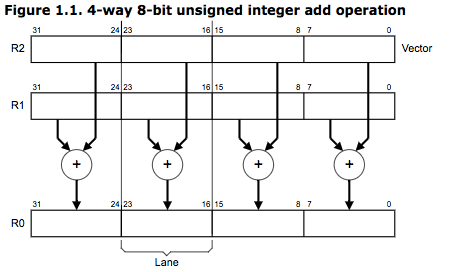
NEON[5]——在现代的软件系统中,当需要在32位微处理器上处理16位数据(如语音)或8位数据(如图片)时,有部分计算单位无法被用到。基于 SIMD(单指令多数据)的并行计算模型可在这种情况下提高计算性能,如本来的一个32位数加法指令,可同时完成4个8位数的加法指令。如下图所示,为 ARMv6 UADD8 R0, R1, R2 指令 ,其利用32位通用寄存器同时进行4个8位数的加法,这样的操作保证了4倍的执行效率而不需要增加额外的加法计算单元。从 ARMv7 架构开始,SIMD 计算模型便通过一组在特定的64位、128位向量寄存器(不同于通用寄存器)上进行操作的指令得到扩展,这组指令便称为 NEON,NEON 技术已经在 ARM Cortex-A 系列处理器上得到支持。NEON 指令由 ARM/Thumb 指令流进行执行,相比需要额外加速设备的加速方法,NEON 简化了软件的开发、调试和集成。
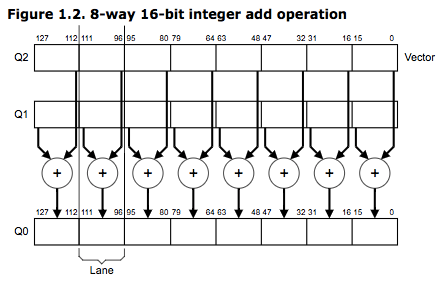
如下图为 VADD.I16 Q0, Q1, Q2 指令对存储在向量寄存器 Q1, Q2 中的128数据以16位为单位进行并行加法。
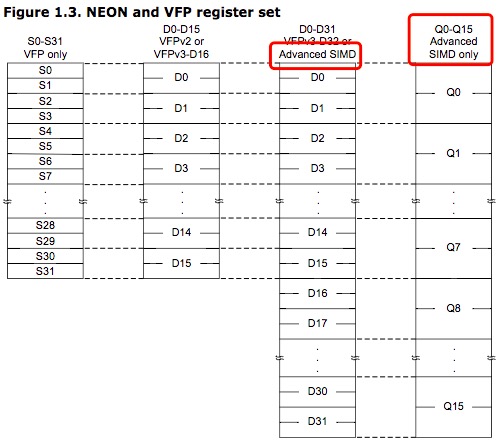
NEON 指令支持8、16、32、64位有符号/无符号整型数,支持32位单精度浮点数,使用 VCVT 指令可进行数据类型的转换。NEON 指令的寄存器组由32位/64位寄存器组成,在 NEON 指令的眼中,寄存器组可被看成16个128位的4字寄存器,既Q0 - Q15,也可被看成32个64位的双字寄存器,既D0 - D31,如下图所示,这种不同的寄存器组视图不需要通过特定的指令进行切换,而是由 NEON 指令来决定执行时需要的寄存器组视图。
要使用最新的 NEON 指令,需要使用最新的 GNU、RealView 编译工具,这两支编译器均支持 NEON 指令集。要使用 NEON 指令,最直接的方式是使用汇编语言,如下代码分别为使用 GNU assembler(Gas) 和 RVCT(RealView Compilation Tools)汇编调用 NEON 指令的函数,其参数的传递和返回均通过 NEON 寄存器。
// using Gas, add -mfpu=neon to the assembler command line
// compilation: arm-none-linux-gnueabi-as -mfpu=neon asm.s
.text
.arm
.global double_elements
double_elements:
vadd.i32 q0,q0,q0
bx lr
.end
// specify a target processor that supports NEON instructions
// armasm --cpu=Cortex-A8 asm.s
AREA RO, CODE, READONLY
ARM
EXPORT double_elements
double_elements
VADD.I32 Q0, Q0, Q0
BX LR
END
在代码中使用 intrinsic 函数和数据类型是使用 NEON 指令的另一种方式,这种方式还会提供如类型检查、自动的寄存器分配等特性。intrinsic 函数的使用类似于 C/C++ 函数接口的使用,但在编译时,intrinsic 函数会被更低层次的指令序列代替,这也意味着工程师能使用高级语言描述更低层次的架构行为,编译器能在编译阶段帮助工程师进行性能上的优化,如下代码实现了上述汇编代码相同的功能。
// NEON intrinsics
// same syntax for GNU & RVCT
// NEON intrinsics with GCC
// arm-none-linux-gnueabi-gcc -mfpu=neon intrinsic.c
// Depending on your toolchain, you might also have to add
// -mfloat-abi=softfp to indicate to the compiler that
// NEON variables must be passed in general purpose registers.
// NEON intrinsics with RVCT
// armcc --cpu=Cortex-A9 intrinsic.c
#include <arm_neon.h>
uint32x4_t double_elements(uint32x4_t input)
{
return(vaddq_u32(input, input));
}
还有一种使用 NEON 指令的方式,那便是由编译器进行自动向量化。由于不使用 NEON 的汇编指令和 intrinsics,所以这种方法能够保持代码的可移植性。由于 C/C++ 语言并不能显示地描述代码的并行行为,所以工程师需要给编译器一些提示,以便编译器能够使用 NEON 指令,如下所示代码。
// GCC
// arm-none-linux-gnueabi-gcc -mfpu=neon -ftree-vectorize -ftree-vectorizer-verbose=1 -c vectorized.c
// RVCT
// armcc --cpu=Cortex-A9 -O3 -Otime --vectorize --fpmode=fast --remarks -c vectorized.c
// 使用 __restrict 保证指针 pa, pb 没有在内存中没有交叠的地方
void add_ints(int * __restrict pa, int * __restrict pb, unsigned int n, int x)
{
unsigned int i;
// n & ~3 使 n 的低2位为0,既 n 为4的倍数。假设此处 int* 是32位整型指针,n 为4,则
// 编译器会将下面的循环使用 VADD.I32 Q, Q, Q 进行优化,Q 为128位寄存器
for(i = 0; i < (n & ~3); i++) pa[i] = pb[i] + x;
}
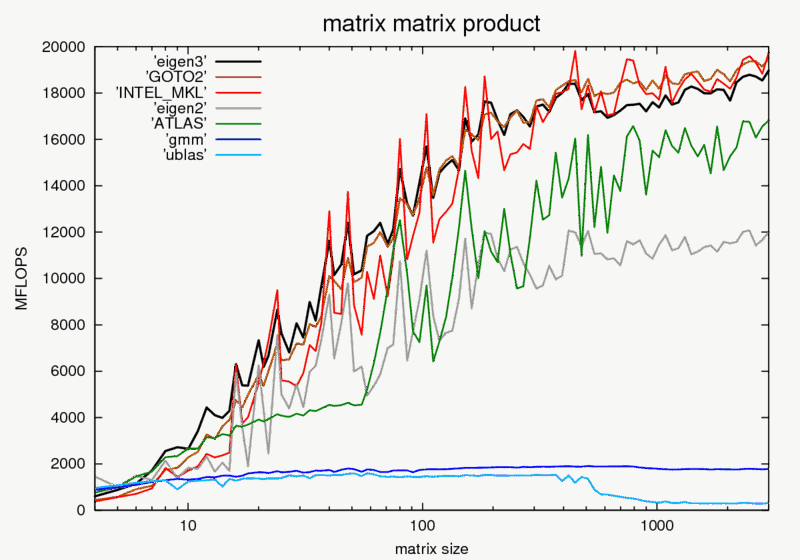
Eigen[6][7][8]——正如前面所说,神经网络的推断计算本质上就是矩阵的运算,所以一个性能突出的 BLAS 库将成为计算的利器。Eigen 是 C/C++ 的高性能线性代数运算库,提供常用的矩阵操作,目前主流的深度学习框架如 TensorFlow,Caffe2等都选择 Eigen 作为 BLAS 库。Eigen 官方对业界常用的 BLAS 库做了 benchmark,比较了 Eigen3, Eigen2, Intel MKL, ACML, GOTO BLAS, ATLAS 的运算性能,在单线程情况下,最重量级的矩阵乘法性能对比如下图所示。由 Eigen 的官方 benchmark 可以看出,在大多数操作上Eigen的优化已经逼近MKL,甚至一些操作超过了 MKL。Eigen 支持多个 SIMD 指令集,包括 ARM 的 NEON 指令集。也就是说,如果目标是 ARM 架构的芯片,那么使用 Eigen 将从 NEON 指令集获得性能增益。
Eigen supports SSE, AVX, AVX512, AltiVec/VSX (On Power7/8 systems in both little and big-endian mode), ARM NEON for 32 and 64-bit ARM SoCs, and now S390x SIMD (ZVector). With SSE, at least SSE2 is required. SSE3, SSSE3 and SSE4 are optional, and will automatically be used if they are enabled. Of course vectorization is not mandatory – you can use Eigen on any CPU. Note: For S390x SIMD, due to lack of hardware support for 32-bit vector float types, only 32-bit ints and 64-bit double support has been added.
- model name : Intel(R) Core(TM)2 Quad CPU Q9400 @ 2.66GHz ( x86_64 )
- compiler: c++ (SUSE Linux) 4.5.0 20100604 [gcc-4_5-branch revision 160292]
ACL(ARM-Compute Library)[3][4]——专为 ARM CPU & GPU 优化设计的计算机视觉和机器学习库,基于 NEON & OpenCL 支持的 SIMD 技术。作为 ARM 自家的加速库,CPU 端基于 NEON 指令集做了许多高性能的接口,包括许多常用的图像处理函数、矩阵运算函数、神经网络操作函数等,如下图为 ComputeLibrary/arm_compute/runtime/NEON/NEFunctions.h 文件所提供的函数一览,位操作、直方图均衡化、矩阵乘法、卷积、池化、BN应有尽有,接口粒度有粗有细。
/* Header regrouping all the NEON functions */
#include "arm_compute/runtime/NEON/functions/NEAbsoluteDifference.h"
#include "arm_compute/runtime/NEON/functions/NEAccumulate.h"
#include "arm_compute/runtime/NEON/functions/NEActivationLayer.h"
#include "arm_compute/runtime/NEON/functions/NEArithmeticAddition.h"
#include "arm_compute/runtime/NEON/functions/NEArithmeticSubtraction.h"
#include "arm_compute/runtime/NEON/functions/NEBatchNormalizationLayer.h"
#include "arm_compute/runtime/NEON/functions/NEBitwiseAnd.h"
#include "arm_compute/runtime/NEON/functions/NEBitwiseNot.h"
#include "arm_compute/runtime/NEON/functions/NEBitwiseOr.h"
#include "arm_compute/runtime/NEON/functions/NEBitwiseXor.h"
#include "arm_compute/runtime/NEON/functions/NEBox3x3.h"
#include "arm_compute/runtime/NEON/functions/NECannyEdge.h"
#include "arm_compute/runtime/NEON/functions/NEChannelCombine.h"
#include "arm_compute/runtime/NEON/functions/NEChannelExtract.h"
#include "arm_compute/runtime/NEON/functions/NEColorConvert.h"
#include "arm_compute/runtime/NEON/functions/NEConvolution.h"
#include "arm_compute/runtime/NEON/functions/NEConvolutionLayer.h"
#include "arm_compute/runtime/NEON/functions/NEDepthConcatenate.h"
#include "arm_compute/runtime/NEON/functions/NEDepthConvert.h"
#include "arm_compute/runtime/NEON/functions/NEDerivative.h"
#include "arm_compute/runtime/NEON/functions/NEDilate.h"
#include "arm_compute/runtime/NEON/functions/NEDirectConvolutionLayer.h"
#include "arm_compute/runtime/NEON/functions/NEEqualizeHistogram.h"
#include "arm_compute/runtime/NEON/functions/NEErode.h"
#include "arm_compute/runtime/NEON/functions/NEFastCorners.h"
#include "arm_compute/runtime/NEON/functions/NEFillBorder.h"
#include "arm_compute/runtime/NEON/functions/NEFullyConnectedLayer.h"
#include "arm_compute/runtime/NEON/functions/NEGEMM.h"
#include "arm_compute/runtime/NEON/functions/NEGEMMInterleave4x4.h"
#include "arm_compute/runtime/NEON/functions/NEGEMMLowp.h"
#include "arm_compute/runtime/NEON/functions/NEGEMMTranspose1xW.h"
......
使用 ARM-Compute Library 进行推断网络的搭建很方便,如下代码构建了一个 conv1: 3x3 -> BatchNorm -> relu 的小网络。在 LG NEXUS 5 平台上,这个网络进行一次推断的时间为8ms,而使用 Caffe2 进行推断的时间为4.8ms。由于 ARM-Compute Library 现在还处于开发完善阶段,很多操作如 MobileNets 中使用的 Depthwise Seperable Convolution(Group Convolution) 还没有得到支持。
#include "arm_compute/runtime/NEON/NEFunctions.h"
#include "arm_compute/core/Types.h"
#include "utils/Utils.h"
#include <time.h>
#include <iostream>
using namespace arm_compute;
using namespace utils;
void main_mobilenets(int argc, const char **argv)
{
ARM_COMPUTE_UNUSED(argc);
ARM_COMPUTE_UNUSED(argv);
clock_t start, end;
double cpu_time_used;
// The src tensor should contain the input image
Tensor src;
// The weights and biases tensors for MobileNets
Tensor conv1_w;
Tensor conv1_b;
Tensor conv1_bn_b;
Tensor conv1_bn_s;
Tensor conv1_bn_rm;
Tensor conv1_bn_riv;
Tensor out_conv1;
Tensor out_conv1_bn;
Tensor out_conv1_bn_relu;
NEConvolutionLayer conv1;
NEBatchNormalizationLayer conv1_bn;
NEActivationLayer conv1_bn_relu;
/* [Initialize tensors] */
// Initialize src tensor
constexpr unsigned int width_src_image = 160;
constexpr unsigned int height_src_image = 160;
constexpr unsigned int ifm_src_img = 3;
const TensorShape src_shape(width_src_image, height_src_image, ifm_src_img);
src.allocator()->init(TensorInfo(src_shape, 1, DataType::F32));
// Initialize tensors of conv1
constexpr unsigned int kernel_x_conv1 = 3;
constexpr unsigned int kernel_y_conv1 = 3;
constexpr unsigned int ofm_conv1 = 16;
const TensorShape weights_shape_conv1(kernel_x_conv1, kernel_y_conv1, src_shape.z(), ofm_conv1);
const TensorShape biases_shape_conv1(weights_shape_conv1[3]);
const TensorShape out_shape_conv1(src_shape.x() / 2, src_shape.y() / 2, weights_shape_conv1[3]);
conv1_w.allocator()->init(TensorInfo(weights_shape_conv1, 1, DataType::F32));
conv1_b.allocator()->init(TensorInfo(biases_shape_conv1, 1, DataType::F32));
out_conv1.allocator()->init(TensorInfo(out_shape_conv1, 1, DataType::F32));
// Initialize tensors of conv1_bn
const TensorShape b_shape_conv1_bn(weights_shape_conv1[3]);
const TensorShape s_shape_conv1_bn(weights_shape_conv1[3]);
const TensorShape rm_shape_conv1_bn(weights_shape_conv1[3]);
const TensorShape riv_shape_conv1_bn(weights_shape_conv1[3]);
const TensorShape out_shape_conv1_bn(out_shape_conv1);
conv1_bn_b.allocator()->init(TensorInfo(b_shape_conv1_bn, 1, DataType::F32));
conv1_bn_s.allocator()->init(TensorInfo(s_shape_conv1_bn, 1, DataType::F32));
conv1_bn_rm.allocator()->init(TensorInfo(rm_shape_conv1_bn, 1, DataType::F32));
conv1_bn_riv.allocator()->init(TensorInfo(riv_shape_conv1_bn, 1, DataType::F32));
out_conv1_bn.allocator()->init(TensorInfo(out_shape_conv1_bn, 1, DataType::F32));
// Initialize tensors of conv1_bn_relu
const TensorShape out_shape_conv1_bn_relu(out_shape_conv1);
out_conv1_bn_relu.allocator()->init(TensorInfo(out_shape_conv1_bn_relu, 1, DataType::F32));
/* -----------------------End: [Initialize tensors] */
/* [Configure functions] */
conv1.configure(&src, &conv1_w, &conv1_b, &out_conv1, PadStrideInfo(2, 2, 1, 1));
conv1_bn.configure(&out_conv1, &out_conv1_bn, &conv1_bn_rm, &conv1_bn_riv, &conv1_bn_b, &conv1_bn_s, 0.0001);
conv1_bn_relu.configure(&out_conv1_bn, &out_conv1_bn_relu, ActivationLayerInfo(ActivationLayerInfo::ActivationFunction::RELU));
/* -----------------------End: [Configure functions] */
/* [Allocate tensors] */
// Now that the padding requirements are known we can allocate the images:
src.allocator()->allocate();
conv1_w.allocator()->allocate();
conv1_b.allocator()->allocate();
out_conv1.allocator()->allocate();
conv1_bn_b.allocator()->allocate();
conv1_bn_s.allocator()->allocate();
conv1_bn_rm.allocator()->allocate();
conv1_bn_riv.allocator()->allocate();
out_conv1_bn.allocator()->allocate();
out_conv1_bn_relu.allocator()->allocate();
/* -----------------------End: [Allocate tensors] */
/* [Initialize weights and biases tensors] */
// Once the tensors have been allocated, the src, weights and biases tensors can be initialized
// ...
/* -----------------------[Initialize weights and biases tensors] */
/* [Execute the functions] */
start = clock();
conv1.run();
conv1_bn.run();
conv1_bn_relu.run();
end = clock();
cpu_time_used = ((double) (end - start)) / CLOCKS_PER_SEC;
std::cout << "time: " << cpu_time_used * 1000 << "ms" << std::endl;
/* -----------------------End: [Execute the functions] */
}
/** Main program for mobilenets test
*
* The example implements the following mobilenets architecture:
*
*
* @param[in] argc Number of arguments
* @param[in] argv Arguments
*/
int main(int argc, const char **argv)
{
return utils::run_example(argc, argv, main_mobilenets);
}
NNPACK[14]——NNPACK 由 facebook 开发,是一个加速神经网络推断计算的加速包,NNPACK可以在多核 CPU 平台上提高卷积层计算性能。NNPACK采用的快速卷积算法基于 Fourier transform 算法和 Winograd transform 算法。下表是 NNPACK 在官网上展出的跟 caffe 的性能比较[14],由表可以看出,在常见网络结构的卷积操作中,NNPACK 都有一个很大算力提升(Forward propagation performance on Intel Core i7 6700K vs BVLC Caffe master branch as of March 24, 2016)。NNPACK 对 Fast Fourier transform,Winograd transform,Matrix-matrix multiplication(GEMM),Matrix-vector multiplication (GEMV),Max-pooling 做了特别的优化。NNPACK 已经被许多深度学习框架用于底层加速,包括 facebook 自家的 Caffe2。
| Library | Caffe | NNPACK | NNPACK | NNPACK |
|---|---|---|---|---|
| Algorithm | im2col + sgemm | FFT-8x8 | FFT-16x16 | Winograd F(6x6, 3x3) |
| AlexNet:conv2 | 315 ms | 129 ms | 86 ms | N/A |
| AlexNet:conv3 | 182 ms | 87 ms | 44 ms | 70 ms |
| AlexNet:conv4 | 264 ms | 109 ms | 56 ms | 89 ms |
| AlexNet:conv5 | 177 ms | 77 ms | 40 ms | 64 ms |
| VGG-A:conv1 | 255 ms | 303 ms | 260 ms | 404 ms |
| VGG-A:conv2 | 902 ms | 369 ms | 267 ms | 372 ms |
| VGG-A:conv3.1 | 566 ms | 308 ms | 185 ms | 279 ms |
| VGG-A:conv3.2 | 1091 ms | 517 ms | 309 ms | 463 ms |
| VGG-A:conv4.1 | 432 ms | 228 ms | 149 ms | 188 ms |
| VGG-A:conv4.2 | 842 ms | 402 ms | 264 ms | 329 ms |
| VGG-A:conv5 | 292 ms | 141 ms | 83 ms | 114 ms |
| OverFeat:conv2 | 424 ms | 158 ms | 73 ms | N/A |
| OverFeat:conv3 | 250 ms | 69 ms | 74 ms | 54 ms |
| OverFeat:conv4 | 927 ms | 256 ms | 272 ms | 173 ms |
| OverFeat:conv5 | 1832 ms | 466 ms | 524 ms | 315 ms |
NNPACK 主要支持下列的神经网络操作:
- Convolutional layer
- Training-optimized forward propagation (nnp_convolution_output)
- Training-optimized backward input gradient update (nnp_convolution_input_gradient)
- Training-optimized backward kernel gradient update (nnp_convolution_kernel_gradient)
- Inference-optimized forward propagation (nnp_convolution_inference)
- Fully-connected layer
- Training-optimized forward propagation (nnp_fully_connected_output)
- Inference-optimized forward propagation (nnp_fully_connected_inference)
- Max pooling layer
- Forward propagation, both for training and inference, (nnp_max_pooling_output)
- ReLU layer (with parametrized negative slope)
- Forward propagation, both for training and inference, optionally in-place, (nnp_relu_output)
- Backward input gradient update (nnp_relu_input_gradient)
- Softmax layer
- Forward propagation, both for training and inference, optionally in-place (nnp_softmax_output)
NCNN[15]——NCNN 由腾讯研发开源,是一个专门为移动端进行优化的神经网络推断计算框架,其不依赖于其他第三方库,网络操作如卷积、池化等均由框架自己实现,这是 NCNN 相对于 Caffe2、TensorFlow 等所不同的一个特点。目前, NCNN 只支持对深度学习训练框架 Caffe[16] 导出的模型进行解析。
使用 Caffe 进行模型的训练,当训练完成时,框架会导出一个存有训练得到的网络各层的参数文件 *.caffemodel,配合描述网络结构的文件 deploy.prototxt,即可调用 Caffe 的推断接口生成对应的推断器,在输入图像即可进行推断,如下为使用 Caffe 的 Python 接口进行推断的代码示意[16]:
model = 'deploy.prototxt' # model ready to deploy
weights = 'net_4800.caffemodel'
caffe.set_mode_gpu()
caffe.set_device(0)
net = caffe.Net(model, weights, 'test') # init a predictor
# input image and get predict score
image = imread('example_4.png')
res = net.forward({image})
prob = res{1}
NCNN 并不提供网络训练的相应操作,其起到的作用与上述代码一致——读入网络参数与结构,进行前向推断运算。由于 Caffe 模型与 NCNN 模型并不完全兼容,所以 在使用 NCNN 之前需要先对 Caffe 模型进行转换,这个过程由 NCNN 所提供的转换工具 caffe2ncnn 完成,NCNN 在本地进行编译时在 ncnn/build/tools 下会生成一系列的工具程序。除了模型转换程序,NCNN 还提供模型的加密程序 ncnn2mem,用于对网络结构文件和网络参数文件进行加密。读取加密模型与读取非加密模型需要使用不同的接口,如下代码所示:
// 读取非加密文件
ncnn::Net net;
net.load_param("alexnet.param");
net.load_model("alexnet.bin");
// 读取加密文件
ncnn::Net net;
net.load_param_bin("alexnet.param.bin");
net.load_model("alexnet.bin");
NCNN 的推断过程很方便,在 ncnn/examples/squeezenet.cpp 下有例程,核心操作如下代码所示。相比 ACL、NNPACK 等网络操作库,使用 NCNN 不同再重新定义推断的网络,这提高了 Caffe 所导出模型的通用性,在对模型进行修改后不用对推断的代码进行修改。
static int detect_squeezenet(const cv::Mat& bgr, std::vector<float>& cls_scores)
{
ncnn::Net squeezenet;
squeezenet.load_param("squeezenet_v1.1.param"); // 加载网络参数文件
squeezenet.load_model("squeezenet_v1.1.bin"); // 加载网络结构文件
// 将 OpenCV2 的输入图像进行格式转换
ncnn::Mat in = ncnn::Mat::from_pixels_resize(bgr.data, ncnn::Mat::PIXEL_BGR, bgr.cols, bgr.rows, 227, 227);
const float mean_vals[3] = {104.f, 117.f, 123.f};
in.substract_mean_normalize(mean_vals, 0);
ncnn::Extractor ex = squeezenet.create_extractor();
ex.set_light_mode(true);
ex.input("data", in); // 输入推断数据
ncnn::Mat out;
ex.extract("prob", out); // 获得推断结果
cls_scores.resize(out.c);
for (int j=0; j<out.c; j++)
{
const float* prob = out.data + out.cstep * j;
cls_scores[j] = prob[0];
}
return 0;
}
TVM[18]——TVM 提供了一个 Tensor 的中间描述层,围绕着这个中间描述层,TVM 提供了操作 Tensor 的计算接口,并能向下生成各个平台的运行代码,从而向上提供给各类深度学习框架使用。TVM 的工作流程分为如下几个步骤:1. 描述 Tensor 和计算规则;2. 定义计算规则的运算方式;3. 编译出所需平台的运行代码;4. 集成生成函数。
TVM 使用类似于 TensorFlow 的计算图模型来定义计算规则,如下代码所示定义了 Tensor A,B,C 进行向量加的计算规则,其使用 lamda 表达式来描述 Tensor 中各个元素之间的计算关系。在此阶段不会有任何具体的运算发生:
n = tvm.var("n")
A = tvm.placeholder((n,), name='A')
B = tvm.placeholder((n,), name='B')
C = tvm.compute(A.shape, lambda i: A[i] + B[i], name="C")
定义完计算规则后,计算规则本身是可以有多种不同的实现的。如上述的向量加,由于向量各个元素之间的运算并不存在依赖关系,所以可以使用并行的方式来进行计算,但是这在不同的设备上,其实现的代码则千差万别。TVM 要求工程师为计算规则定义一个对应的 schedule,用来描述计算规则的运算方式,以便能针对不同的计算平台生成相应的代码,我们可以把 schedule 理解为计算规则的转换方式,如下代码定义了一个 schedule,默认情况下,schedule 将以串行的方式来对计算规则进行运算。此处我们使用 split 函数来对串行的运算方式进行分解,使之能以 factor 个元素为单位对运算方式进行分解:
s = tvm.create_schedule(C.op)
# schedule 的默认运算方式,其效果与如下代码等同
# for (int i = 0; i < n; ++i) {
# C[i] = A[i] + B[i];
# }
bx, tx = s[C].split(C.op.axis[0], factor=64)
# 使用 split 对串行的运算方式进行分解,其效果与如下代码等同
# for (int bx = 0; bx < ceil(n / 64); ++bx)
# {
# for (int tx = 0; tx < 64; ++tx)
# {
# int i = bx * 64 + tx;
# if (i < n)
# C[i] = A[i] + B[i];
# }
# }
当定义完 schedule 后,就可以对特定计算平台进行绑定,编译出所需的代码,如下代码将 schedule 所返回的两个迭代子与 NVIDIA GPU 的 CUDA 计算模型进行绑定,bx 为 s 的第一层迭代子,其对应 CUDA 中的线程块(BLOCK),在上述配置下,将有 ceil(n / 64) 个线程块运行在 GPU 上;tx 为 s 的第二层迭代子,每次迭代将对一个 C 的元素进行计算,在 GPU 上每次迭代将由一个线程(THREAD)来负责计算,即每个线程块中将配置 64 个线程。绑定完成后,我们可以调用 build 函数生成对应的 TVM 函数,build 函数会接收 schedule、输入输出的 tensor、目标语言、目标 host等作为参数,生成一个指定语言的函数接口(默认为 Python)。此处生成的 fadd_cuda 是 CUDA 核函数的一个 warpper,使用它便可将运算在 NVIDIA GPU 上执行。
s[C].bind(bx, tvm.thread_axis("blockIdx.x"))
s[C].bind(tx, tvm.thread_axis("threadIdx.x"))
fadd_cuda = tvm.build(s, [A, B, C], "cuda", target_host="llvm", name="myadd")
生成函数接口之后,我们可以使用任意语言来调用该函数接口,此处我们仍然是用 Python 来进行调用:1. 先声明一个 GPU context, 使之能与我们 CPU 端的线程形成对应关系;2. tvm.nd.array 将数据拷贝到 GPU 之上;3. 执行运算。
ctx = tvm.gpu(0)
n = 1024
a = tvm.nd.array(np.random.uniform(size=n).astype(A.dtype), ctx)
b = tvm.nd.array(np.random.uniform(size=n).astype(B.dtype), ctx)
c = tvm.nd.array(np.zeros(n, dtype=C.dtype), ctx)
fadd_cuda(a, b, c)
np.testing.assert_allclose(c.asnumpy(), a.asnumpy() + b.asnumpy())
我们可以将生成的 CUDA 代码输入示意 fadd_cuda.imported_modules[0].get_source():
// -----CUDA code-----
extern "C" __global__ void myadd__kernel0(float* __restrict__ C, float* __restrict__ A, float* __restrict__ B, int n) {
if (((int)blockIdx.x) < ((n + -127) / 64)) {
C[((((int)blockIdx.x) * 64) + ((int)threadIdx.x))] =
(A[((((int)blockIdx.x) * 64) + ((int)threadIdx.x))] + B[((((int)blockIdx.x) * 64) + ((int)threadIdx.x))]);
} else {
if ((((int)blockIdx.x) * 64) < (n - ((int)threadIdx.x))) {
C[((((int)blockIdx.x) * 64) + ((int)threadIdx.x))] =
(A[((((int)blockIdx.x) * 64) + ((int)threadIdx.x))] + B[((((int)blockIdx.x) * 64) + ((int)threadIdx.x))]);
}
}
}
而当我们希望使用 OpenCL 的计算设备时,则可以选择生成 OpenCL 所需的代码,并是用 fadd_cl.imported_modules[0].get_source() 查看其生成的 OpenCL 代码:
fadd_cl = tvm.build(s, [A, B, C], "opencl", name="myadd")
ctx = tvm.cl(0)
n = 1024
a = tvm.nd.array(np.random.uniform(size=n).astype(A.dtype), ctx)
b = tvm.nd.array(np.random.uniform(size=n).astype(B.dtype), ctx)
c = tvm.nd.array(np.zeros(n, dtype=C.dtype), ctx)
fadd_cl(a, b, c)
// ------opencl code------
__kernel void myadd__kernel0(__global float* restrict C, __global float* restrict A, __global float* restrict B, int n) {
if (((int)get_group_id(0)) < ((n + -127) / 64)) {
C[((((int)get_group_id(0)) * 64) + ((int)get_local_id(0)))] =
(A[((((int)get_group_id(0)) * 64) + ((int)get_local_id(0)))] + B[((((int)get_group_id(0)) * 64) + ((int)get_local_id(0)))]);
} else {
if ((((int)get_group_id(0)) * 64) < (n - ((int)get_local_id(0)))) {
C[((((int)get_group_id(0)) * 64) + ((int)get_local_id(0)))] =
(A[((((int)get_group_id(0)) * 64) + ((int)get_local_id(0)))] + B[((((int)get_group_id(0)) * 64) + ((int)get_local_id(0)))]);
}
}
}
正如 TVM 对自身的介绍所说,其希望能搭建深度学习框架与后端计算设备之间的桥梁。这是一项很有雄心,同时也特别繁杂的工作。
总结
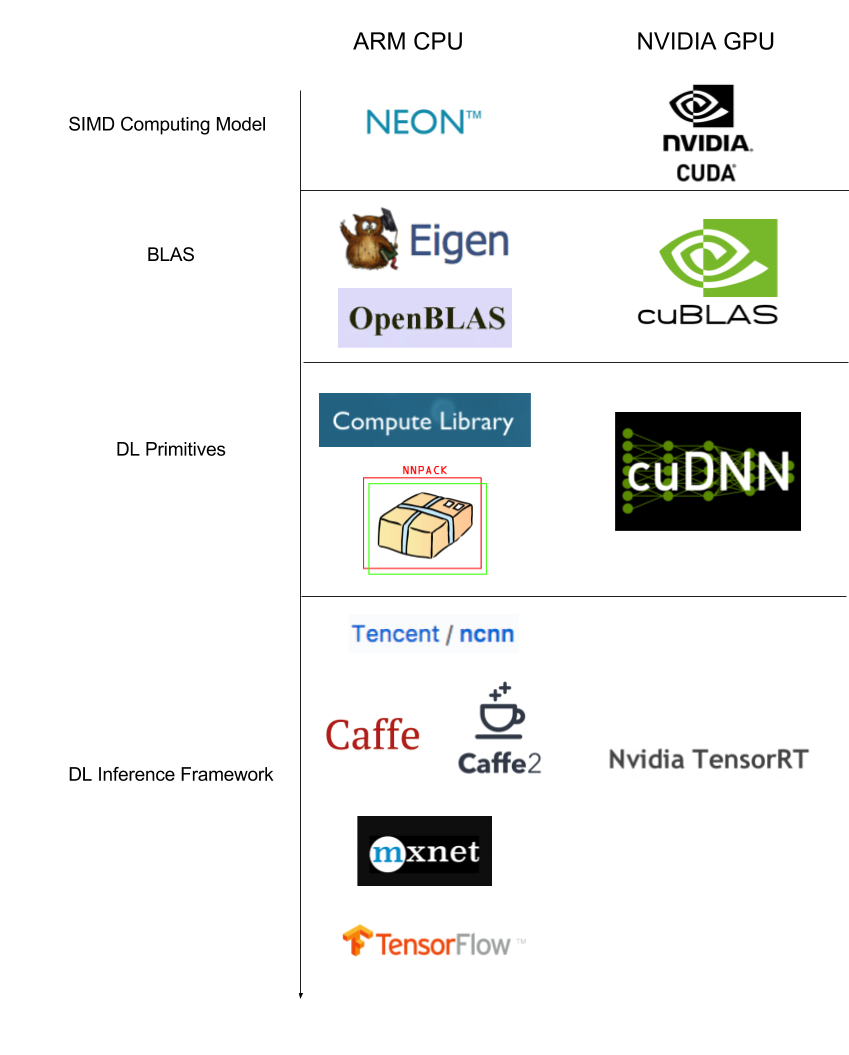
本文总结了现阶段工业界在移动端设备进行卷积神经网络推断的方法,在软件的每个层次上都总结了具有代表性的解决方案,下图是这些解决方案的一个层次结构图。由于深度学习的训练阶段所采用的技术方案实际上已经被 NVIDIA 所垄断,所以我们给出了 NVIDIA 提供的技术栈作为横向的比较对象。
引用
[1] csarron@github(2017), Embedded and mobile deep learning research resources. https://github.com/csarron/emdl
[2] Wu, Jiaxiang, et al. “Quantized convolutional neural networks for mobile devices.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
[3] Arm@youtube(May 24, 2017), Compute Library: optimizing computer vision and machine learning on ARM. https://www.youtube.com/watch?v=xwESWqdJt_Y
[4] Arm(2017), The ARM Computer Vision and Machine Learning library is a set of functions optimised for both ARM CPUs and GPUs using SIMD technologies. https://arm-software.github.io/ComputeLibrary/v17.03.1/index.xhtml
[5] Arm(2009), Introducing NEON Development Article. http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dht0002a/BABIIFHA.html
[6] Eigen(2017), Eigen Home Page. https://eigen.tuxfamily.org/dox/GettingStarted.html
[7] Zhihu(2017), 矩阵运算库blas, cblas, openblas, atlas, lapack, mkl之间有什么关系,在性能上区别大吗?. https://www.zhihu.com/question/27872849
[8] Eigen(2017), Benchmark. http://eigen.tuxfamily.org/index.php?title=Benchmark
[9] petewarden.com(2015), Why GEMM is at the heart of deep learning. https://petewarden.com/2015/04/20/why-gemm-is-at-the-heart-of-deep-learning/
[10] Jia, Yangqing. Learning semantic image representations at a large scale. University of California, Berkeley, 2014.
[11] timdettmers.com(2015), Understanding Convolution in Deep Learning. http://timdettmers.com/2015/03/26/convolution-deep-learning/
[12] Wikipedia(2017), 卷积. https://zh.wikipedia.org/wiki/%E5%8D%B7%E7%A7%AF
[13] zouxy09的专栏(2015), 图像卷积与滤波的一些知识点. http://http://blog.csdn.net/zouxy09/article/details/49080029
[14] Maratyszcza@github(2017), NNPACK. https://github.com/Maratyszcza/NNPACK
[15] Tencent@github(2017), NCNN. https://github.com/Tencent/ncnn
[16] BVLC@github(2017), Using a Trained Network: Deploy. https://github.com/BVLC/caffe/wiki/Using-a-Trained-Network:-Deploy
[17] ruyiweicas@csdn, Ubuntu16.04—腾讯NCNN框架入门到应用. http://blog.csdn.net/best_coder/article/details/76201275
[18] TVM(2017), Tutorial of TVM. http://docs.tvmlang.org/tutorials/index.html